Medizinische Universität zu Lübeck
|
Institut für
Theoretische Informatik
Medizinische Universität zu Lübeck |
Lübecker Hochschultag
15. November 2001 Distributed Systems
Distributed SystemsThe Problem of the Byzantine Generals
(here: the Roman Centurions)
The Background:
The year is 50 B.C. Gaul is entirely occupied by the Romans. Well not entirely! One small village of indomitable Gauls still holds out against the invaders.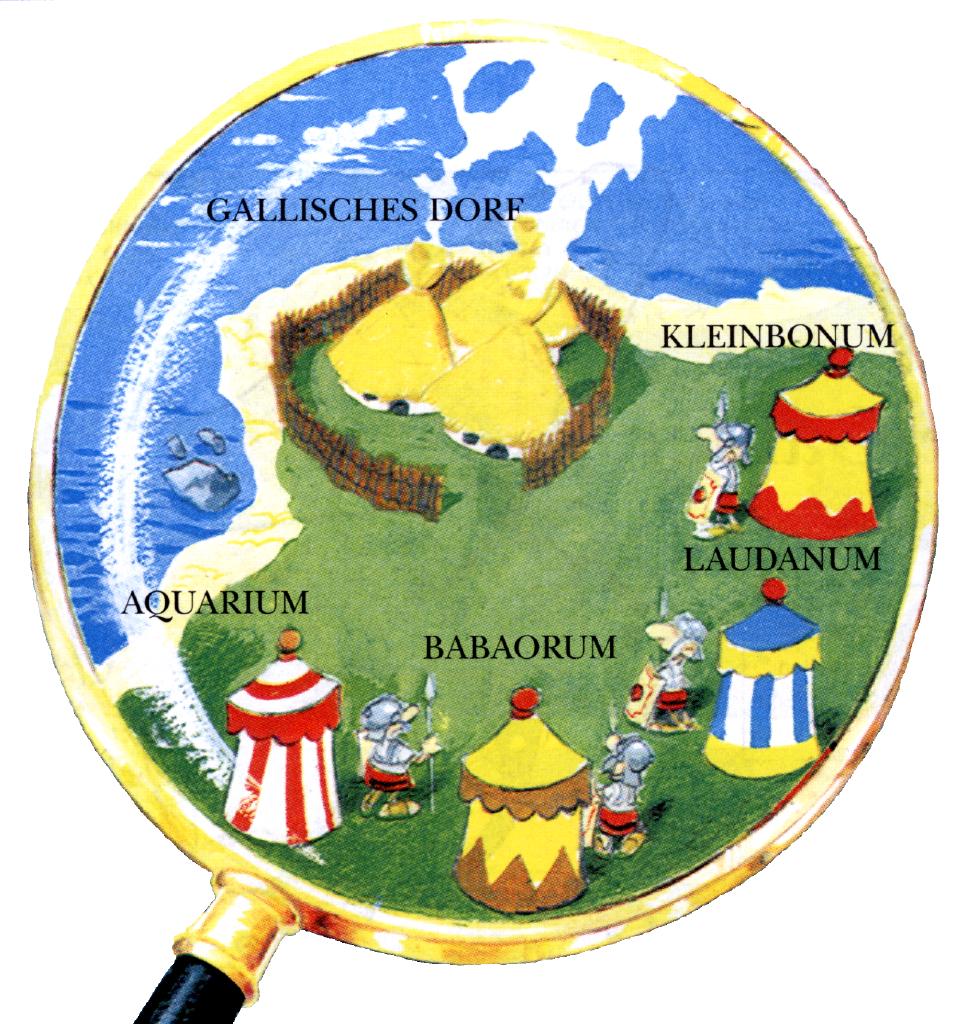
Around the village there are several Roman camps waiting for a good opportunity to attack. But if they do not attack all at the same time, they would be easily defeated by the gauls.
The centurions can inform each other only by messengers. Otherwise they would have to leave their legion alone. But the gauls might bribe some of the centurions. The bribed centurions would transmit contradictory messages, so that some legions would attack while others would begin to retreat.
The Question:
How can the centurions agree on "attack" or "defeat", even though some of them are bribed?
The Solution:
The Centurions can agree on a strategy, if at least two thirds of them are loyal. As an example we describe the procedure, if there are four camps: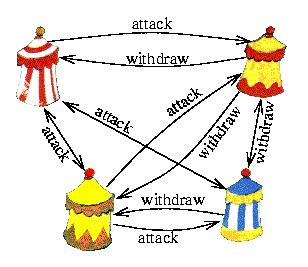
First each centurion sends a message to every other centurion telling him whether he wants to attack or retreat. A loyal centurion will send the same message to all other centurions, but a bribed one will adhere to the instructions of the gauls.

Then each centurion informs each other centurion about all the messages he received during the first step. Again a bribed centurion sends whatever the gauls tell him to. Finally, a loyal centurion decides either for "attack" or "retreat", depending on whether he received more "attack" or more "retreat" messages.
It can be proven that the problem can be solved if at least two thirds of the centurions are loyal. On the other hand, if the gauls bribe at least one third of the centurions, then agreement is not possible.
Why is the Problem Described Important in the Area of Distributed Systems?
In distributed systems there are problems, which do not occur in single computers. An example is finding majority decisions in fault-tolerant systems.And Outside of Gaul:
Further topics within the area of distributed systems are for example broadcasting or synchronisation.Within the topic of broadcasting there two oppositional aims. On the one hand the messages should reach their destinations as fast as possible. On the other hand there should be as little network traffic as possible. A further point is the selection of good ways for the messages, i.e. ways which are either fast or have little load.
If several processes want access to the same file at the same time, conflicts may arise. A similar problem occurs if a process want to read a file, while another process writes into this file. In these cases synchronisation of the processes is necessary, i.e. it must be guaranteed that the first process finishes its work with the file, before another process gets access to the same file.
The pictures are taken from: R. Goscinny and A. Uderzo, Asterix and Latraviata.
Average-Case Studies
Optimist, Pessimist and Joe Average
There are three general way of analysing algorithms:
- the optimistic way, describing the best-case,
- the mean way, describing the average-case, and
- the pessimistic way, describing the worst-case.
The average-case analysis is focused on the expected cost of an algorithm. For several problems the average- and worst case are fare apart from one another. To illustrate this property let us investigate the following example:
Given an integer number of five decimal places. How many places to you have to replace for incrementing the number?
In the worst case the number is 99999 and we have to replace 6 places. Is the number give at random, the last number in not 9 with a probability of 9/10. Hence, we only have to replace one place with this probability. The probability that we have to replace exactly two numbers is 9/10 * 1/10 = 9/100, and so on. In the average we have to replace1 * 9/10 + 2 * 9/100 + 3 * 9/1000
+ 4 * 9/10000 + 5 * 9/100000 + 6 * 1/100000
= 1,1111places. This is very close to the best-case of one place. Furthermore, no matter how long our given number is, the number of places we have to change in the average-case is at most 1,111... .
Asking an optimist how long it takes to increment an decimal number he is optimistic in finding no 9 at the last place. Hence, he has to replace only the last place. A pessimist is sure to find a 99999. And therefore he has to replace all plus one place. Joe Average is sure that he has to replace two places ... with high probability.
The average-case of a problem helps us to analyse the cost of solving the problem for a huge number of instances -- and not only for solving an special instance. The average case complexity of combinatorial problems are of a special interest. For some of these problems the average-case cost is very close to the worst-case, e.g. some puzzle games. The average-case complexity is not only of interest for solving a special problem, but also for communication and security properties. How would like to use a password or a crypto system that is some times secure, but can be decoded very easily for most instances.
Optimizing algorithms is an other area of interest. Assume that we have an algorithm that has a time complexity of n2 for all instances except of a portion of 1/n4 of the inputs of length n. For these inputs it has an time complexity of n3. Then our algorithm will have a quadratic running time for each of the first n2 inputs with a very high probability.
Approximation Algorithms
Good Solutions for Hard Problems
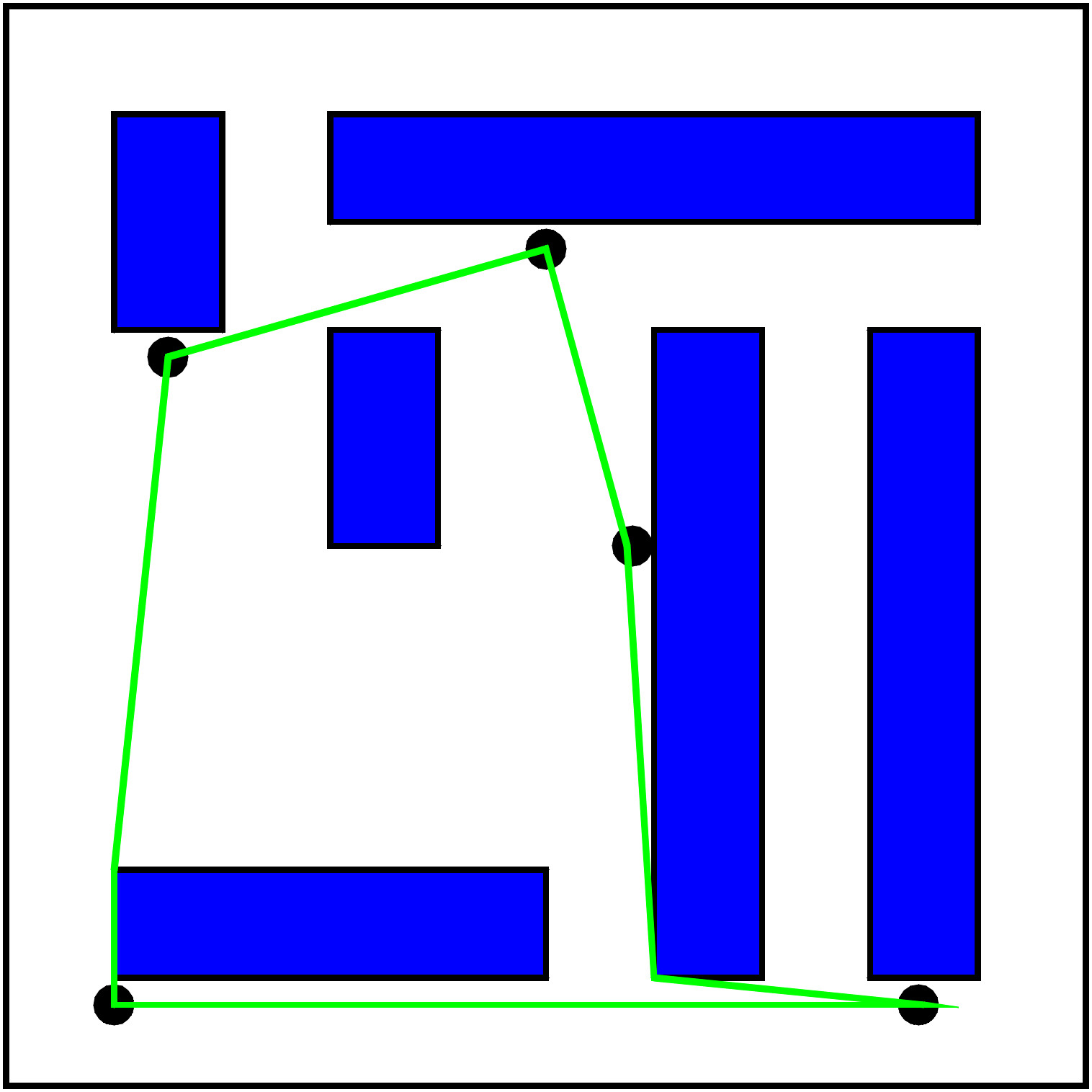
The robot Fred works in the warehouse of a mail order business. One pullover, a pair of socks, one pair of trousers, and a T-shirt shall be shipped with the next order. These items are located at the points 2, 3, 4, and 5. Fred starts in 1. Since the shipping process should be as fast as possible, Fred is requested to visited the points 2, 3, 4, and 5 via the shortest tour possible and then come back to 1 (``round trip'').
Unfortunately, the best algorithms known for computing a shortest round trip visiting n points have a running time of cn for some constant c. This can get very large very quickly, for instance for c = 2 and n = 100 we would have to wait 4 * 106 years.
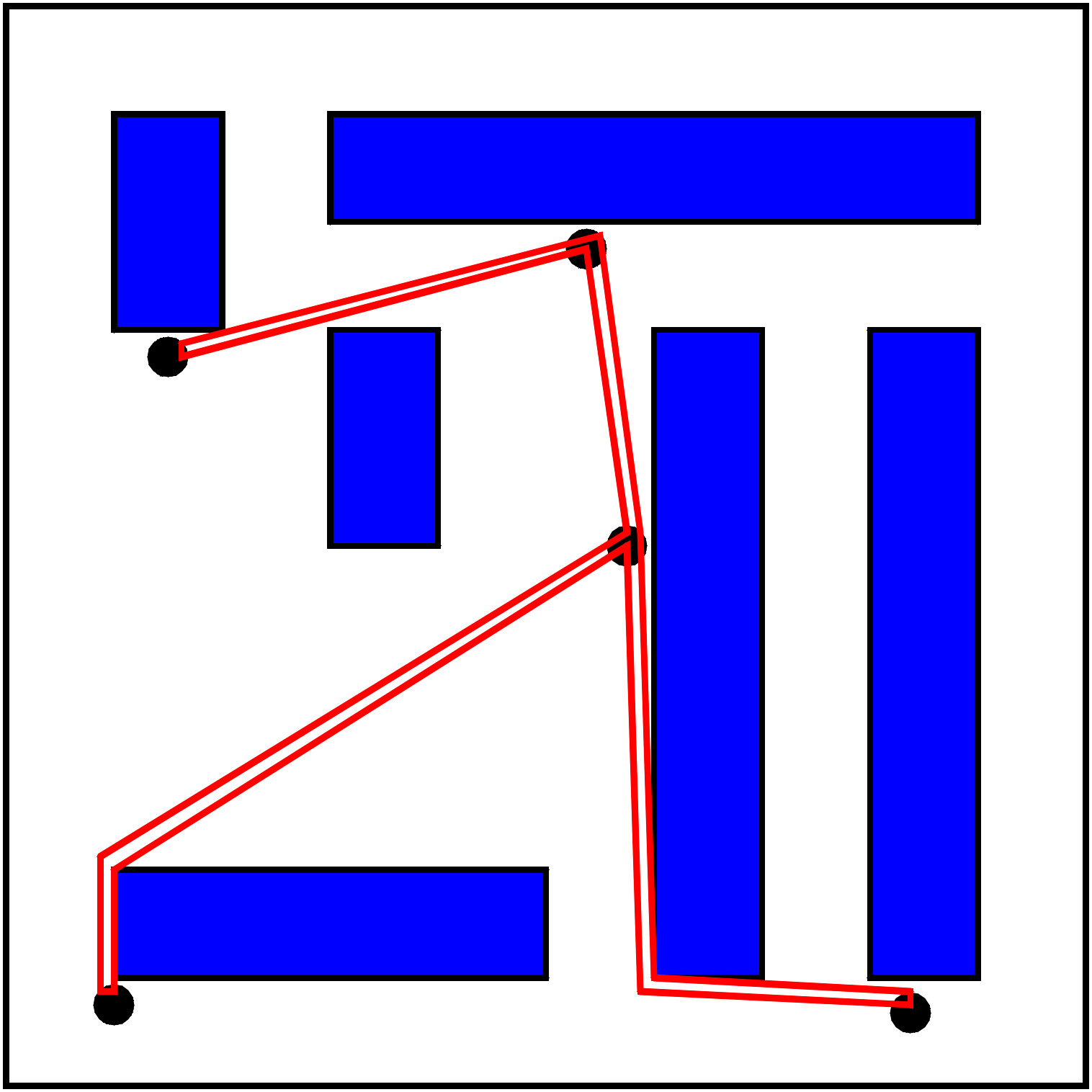
Thus Fred looks for an alternative way: a spanning tree connects the points 1 to 5 with a minimum number of edges. One can efficiently compute a spanning tree such that the sum of the edge lengths is minimal. This takes only time c * n. For c = 1000 and n = 100, we only have to wait 0.1 seconds.
Fred now visits the points 1 to 5 by travelling along the spanning tree: he starts in 1 and then goes to, say, 4 and then further on to 3. Since there is no further point he can reach from 3 on the spanning tree, he goes back to 4 and then also back to 1. Then he visits 2, 1 again, finally reaches 5, and then finishes his journey in 1.
Such an optimum spanning tree trip is at most twice as long as an optimum round trip, since each round trip yields a spanning tree trip by deleting one edge and, furthermore, each edge in a spanning tree trip is visisted exactly twice.
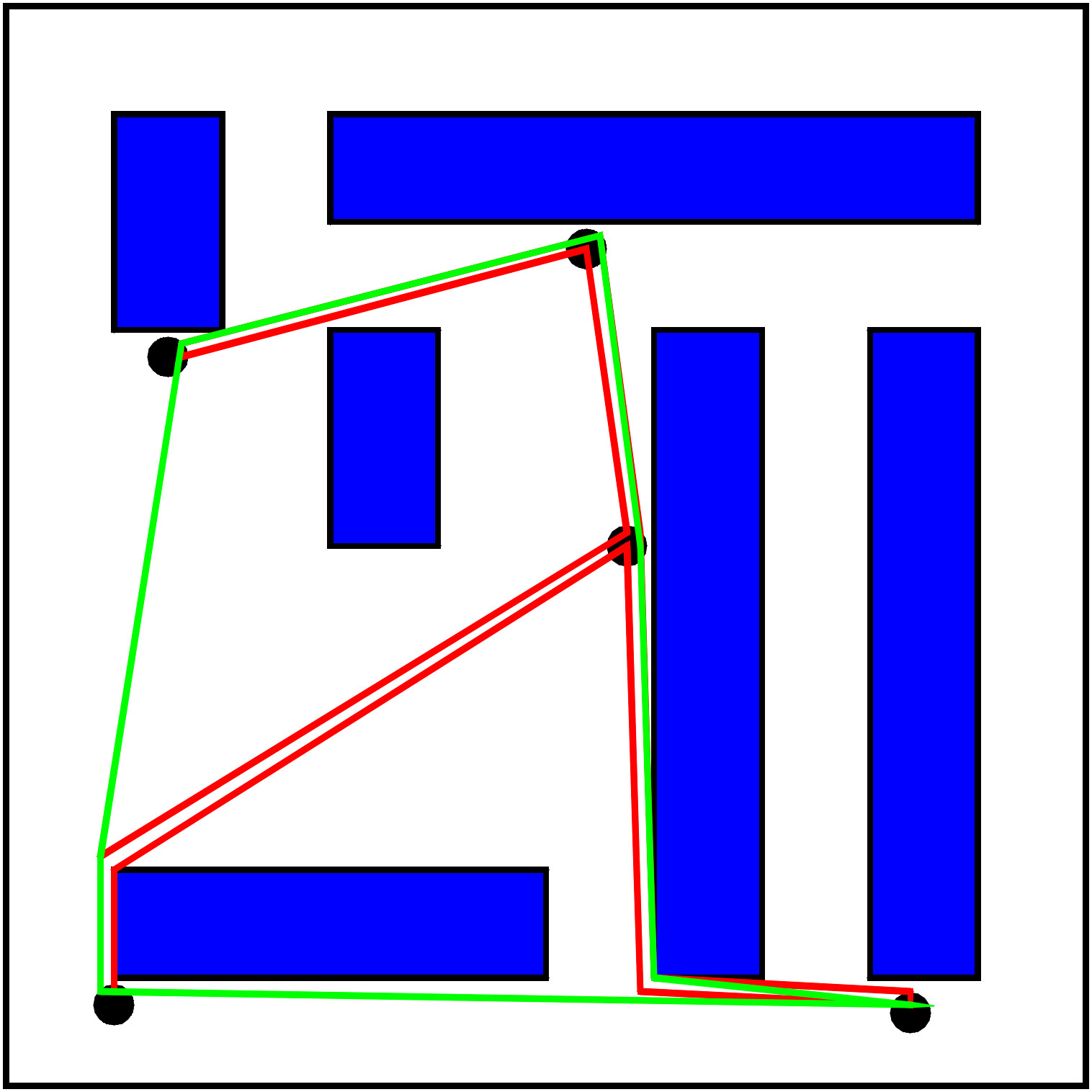
A spanning tree trip can be easily transformed into a round trip that is no longer than the spanning tree trip. We just have to take ``short cuts''. In our example, Fred visist 1, 4, and 3. After that, he does not go back to 4, but goes directly to 2. From 2, he goes directly to 5, too, and then completes the round trip by returning to 1.
Since each short cut cannot enlarge the total distance travelled, Fred obtains a round trip that is at most twice as long as an optimum one. Often, Fred will be better off. In our example, he even finds an optimum round trip.
Neben dem oben beschriebenen Problem der kürzesten Rundreise haben viele weitere praxisrelevante Probleme die Eigenschaft, daß die besten bekannten Algorithmen zur exakten Lösung des Problems exponentiell viel Zeit benötigen. Weitere Beispiele sind das Verteilen von Jobs auf Prozessoren oder das Platzieren von Warenlagern. Hier helfen Approximationsalgorithmen gute Lösungen in akzeptabler Zeit zu finden.
Formal languagesMysterious symbolism with multicolored circles
If we want to indicate something, then this presupposes a language. In such a way programming languages, natural speeches, formel languages, printer languages and many other languages are used in many places. Before we can clarify the meaning of a sentence or a word in any language, we must check whether the sentence or the word belongs to this language. All these languages is common that they indicate an internal structure, with this it is determined, which sentences, words or character series do belong to the language and which do not. For all formally determined languages there exists rules, which have to be checked. Here we want to demonstrate that only a few rules are sufficient, in order to determine a language, for which there exists no program which checks whether a character sequence belongs to or does not.
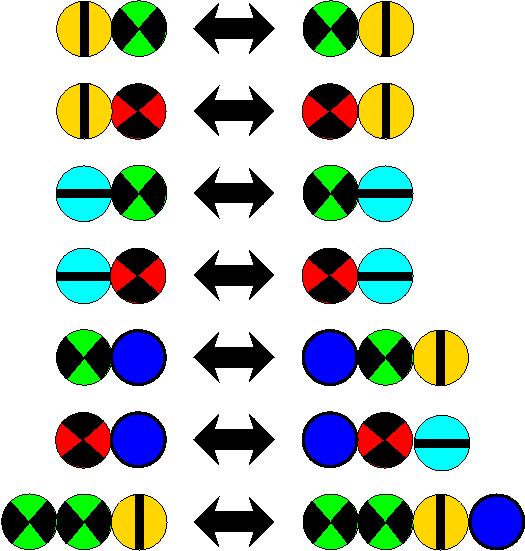
Here we regard a rewriting system, with which we can manipulate sequences of multicolored circles. In order to understand, what is going on, we would like to know, which sequences of multicolored circles into which sequences can be transferred. In a given sequence we may be allowed to replace a connected sequence in accordance with the rules -- here the rules from left to right and also from right to left may be applied. Since we are computer scientists we are in the good position that we can write easily a program for such a task. However, it may surprise: For the rules presented here the Russian Chaitin proved: There is no program, which outputs on any two sequences of multicolored circles whether these can be transferred into one another!
See the following example, it may demonstrate some possible difficulties that will arise here:
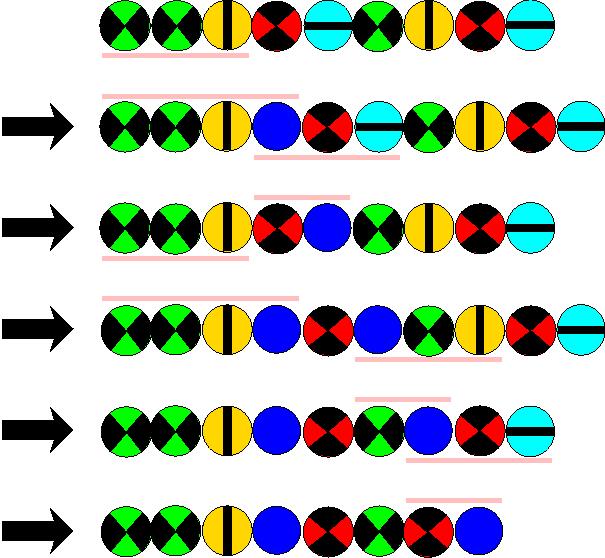
For the rewriting system indicated above one can prove numerous predicates. For example:
- the number of circles with red colour remains constant.
- the number of circles with green colour remains constant.
- if a sequence into another is transferable, then these two sequences have the characteristic that they resemble each other, if all are removed up to the red and green circles.
Finally Chaitin proves: Each program of a programming language with input can be translated into two sequences by above circles with the help of a translation program, such that the following applies: The given program produces an output with its input if and only if the two sequences are in each other transferable with the help of the seven rules.Since one cannot write a program, which decides for all pairs of program and input whether the pair supplies a solution, it is not decidable if the transfer problem for these seven rules has a solution.
SecurityToday and in the future
RSA is a public-key cryptosystem developed by Rivest, Shamir, and Adleman in 1977. This method has many commercial and non-commercial implementations e.g. PGP (Pretty Good Privacy). The algorithm works as follows.
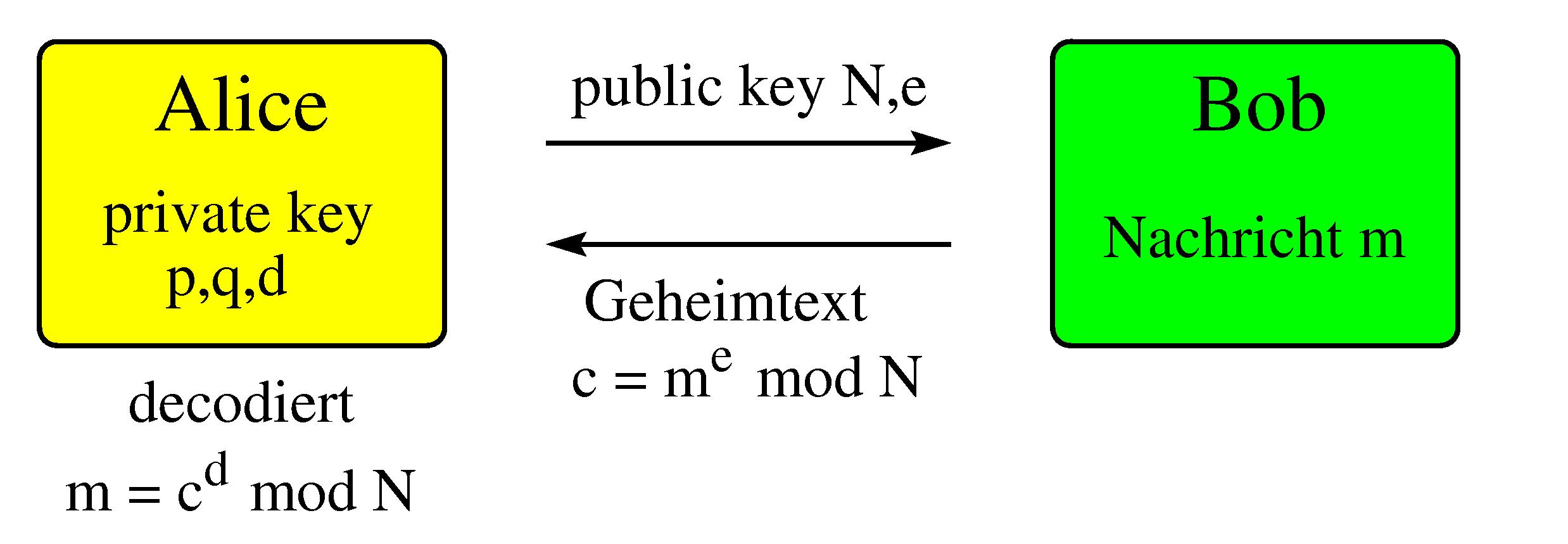 Alice picks randomly two available large primes p and q and computes N = p q and phi = (p-1) (q-1). Then she picks randomly e from {1,2,...,phi} such that gcd(e,phi) = 1 and computes d with (d e) mod phi = 1 (this can be done e.g. by extended Euclid's algorithm).
Alice picks randomly two available large primes p and q and computes N = p q and phi = (p-1) (q-1). Then she picks randomly e from {1,2,...,phi} such that gcd(e,phi) = 1 and computes d with (d e) mod phi = 1 (this can be done e.g. by extended Euclid's algorithm).The numbers
- N and e are the public keys of Alice, that means Alice records them in a table which can be read by Bob and by anybody else, too.
- p, q and d are Alice's private keys, that she keeps as a secret.
If Bob wants to send a message to Alice then he encrypts this message using e and N as follows. He divides the message in Blocks and transforms each block to an integer m less or equal to N (e.g. in ASCII-Code representation). Then Bob computes c = m^e mod N and he sends c to Alice. To decrypt the message Alice computes m = c^d mod N. Correctness of this procedure follows from Euler's Theorem.A peculiar property of RSA is that though the encryption method is known to anybody, it is very difficult to decrypt the original message without appropriate private keys.
How secure are the cryptosystem
The security of many recent cryptosystems is based on fact that for some specific combinatorial problems there are not known (conventional) algorithms which solves these problems efficiently. For RSA this is the prime factorization problem, i.e. from (large) N as above to recompute p and q.
Prime factorization problem
The problem:
For a given integer N compute its prime factors.Example:
(1) N = 15 has prime factors: 3 and 5.
Exercise:
(2) For N = 39199007823998693533 the answer is 4093082899 and 9576890767.
(3) Try to compute the prime factors for N = 2630492240413883318777134293253671517529.The best known (conventional) algorithm to compute prime factors for a given integer N runs (on a modern computer) in
exp(1.9 (ln N)1/3 (ln ln N)2/3)
microseconds. This gives in case (2): 21.26 seconds and in case (3): 5.74 minutes. However for integer N having 65 resp. 400 digits in its decimal representation the algorithm needs 89 days resp. about 1010 years (this is an age of the universe!). A well known conjecture in computer science says that there exists no conventional algorithm which can factorize large integers efficiently. Hence (assuming that this conjecture holds) RSA-System can not be cracked using conventional methods!
Quantum computer -- hard problems efficiently to solve
In 1994 Peter Shor (AT&T) discovered the first quantum algorithm showing that prime factorization of integer N can be done on quantum computers in time c * (ln N)3, where c is a small constant, that is considerably faster than by any known classical algorithm! This means that for any integer of 400 decimal digits a quantum computer can factorize N running in only 3 years (instead of 1010).
Problem: There exist only prototypes of quantum computer so far.
How works the quantum computer?
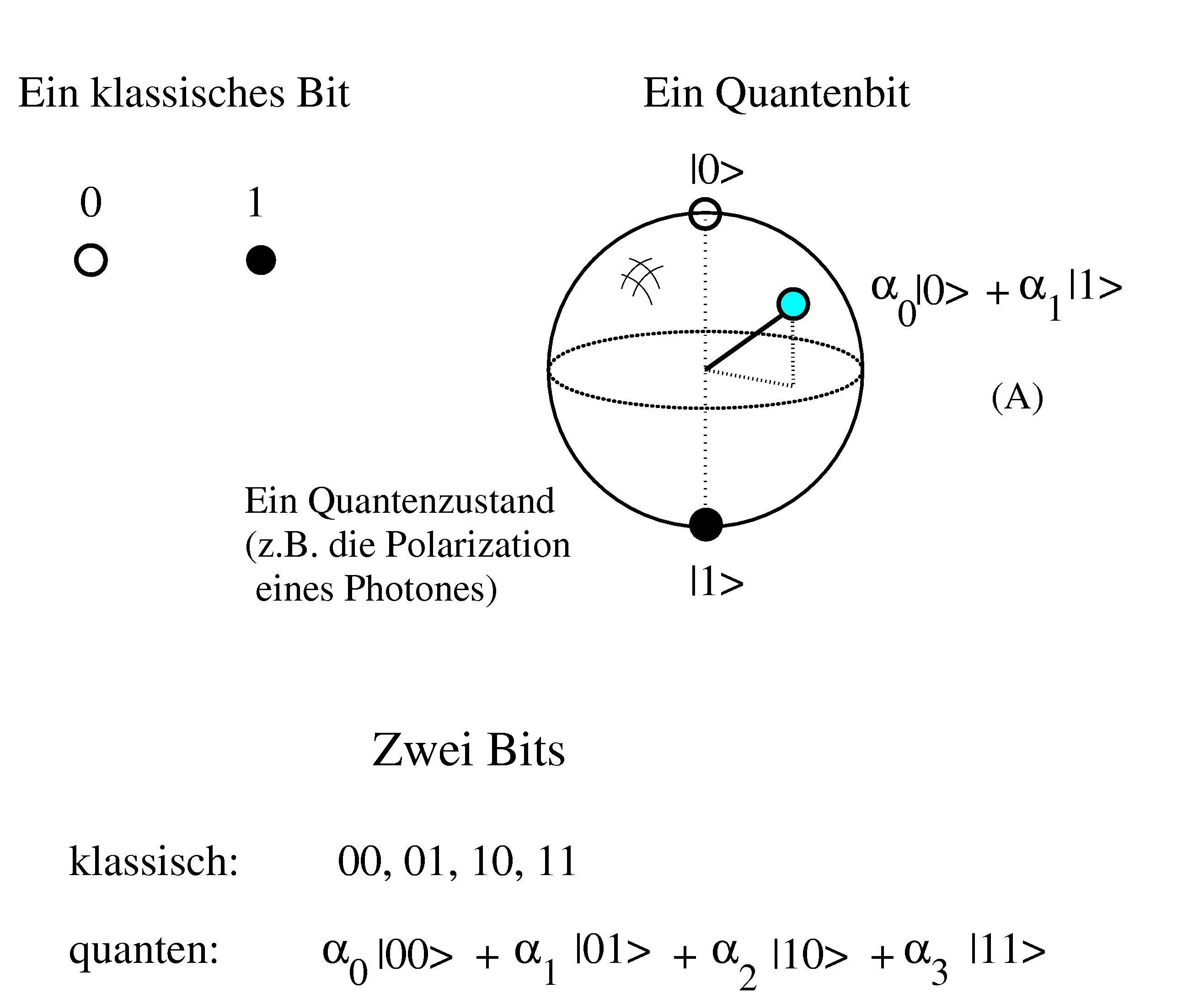
where alpha0, alpha1 are complex numbers, with |alpha0|2 + |alpha1|2 =1.
1-Qubit quantum computer
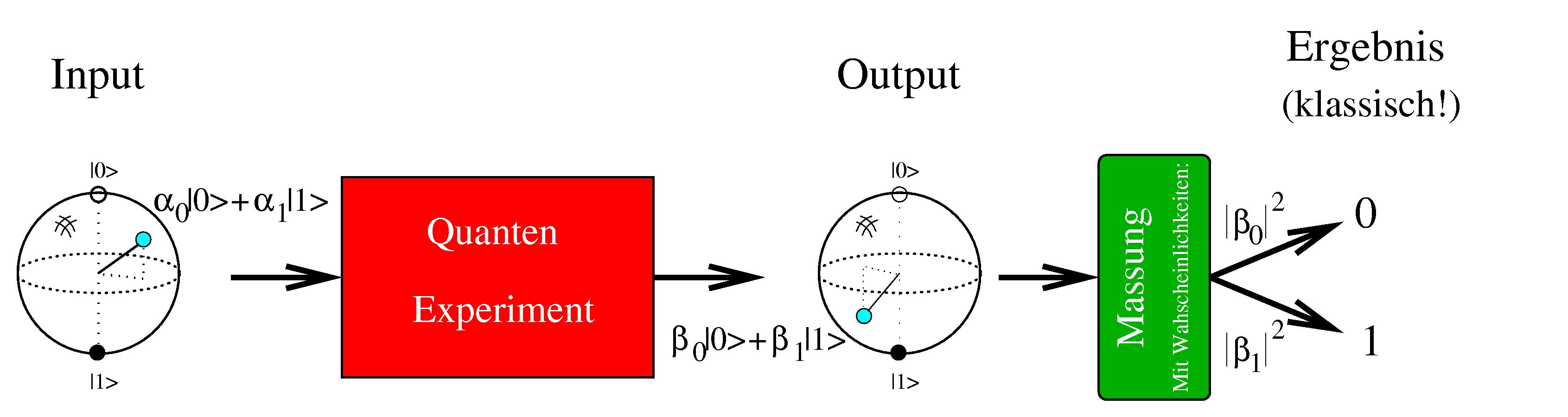
Quantum cryptosystems
Alice sends a sequence of Photons to Bob. Note that the both parts do not need a quantum computer at all.
Important properties
- No-Cloning: No-Cloning: an unknown quantum state cannot be copied.
- Information gain implies disturbance: any attempt to distinguish between two non-orthogonal states introduces disturbance do the signal.
- Irreversibility of measurements: any measurement generally disturbs the state of an object under observation.
As an example let us consider a photon in one of the four possible polarizations.
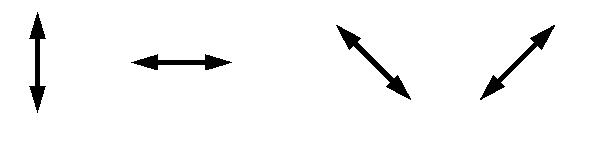
To measure, i.e. to distinguish with certainty between horizontally and vertically, resp. 45- or 135-degree, polarizations one can use a calcite crystal. For the crystal in a specific position horizontally polarized photons pass straight through and vertically polarized photon are deflected to a new path and after the passing in both cases the photons polarisations do not change. However, if a photon polarized in 45- or 135-degrees enters the crystal then it will go through the crystal with probability 1/2 like the horizontally polarized photons or with probability 1/2 like the vertically ones and in both cases it will be re-polarized according to the alternative which occurs and it permanently forget its original polarization!
Bennett and Brassard's scheme (1984)
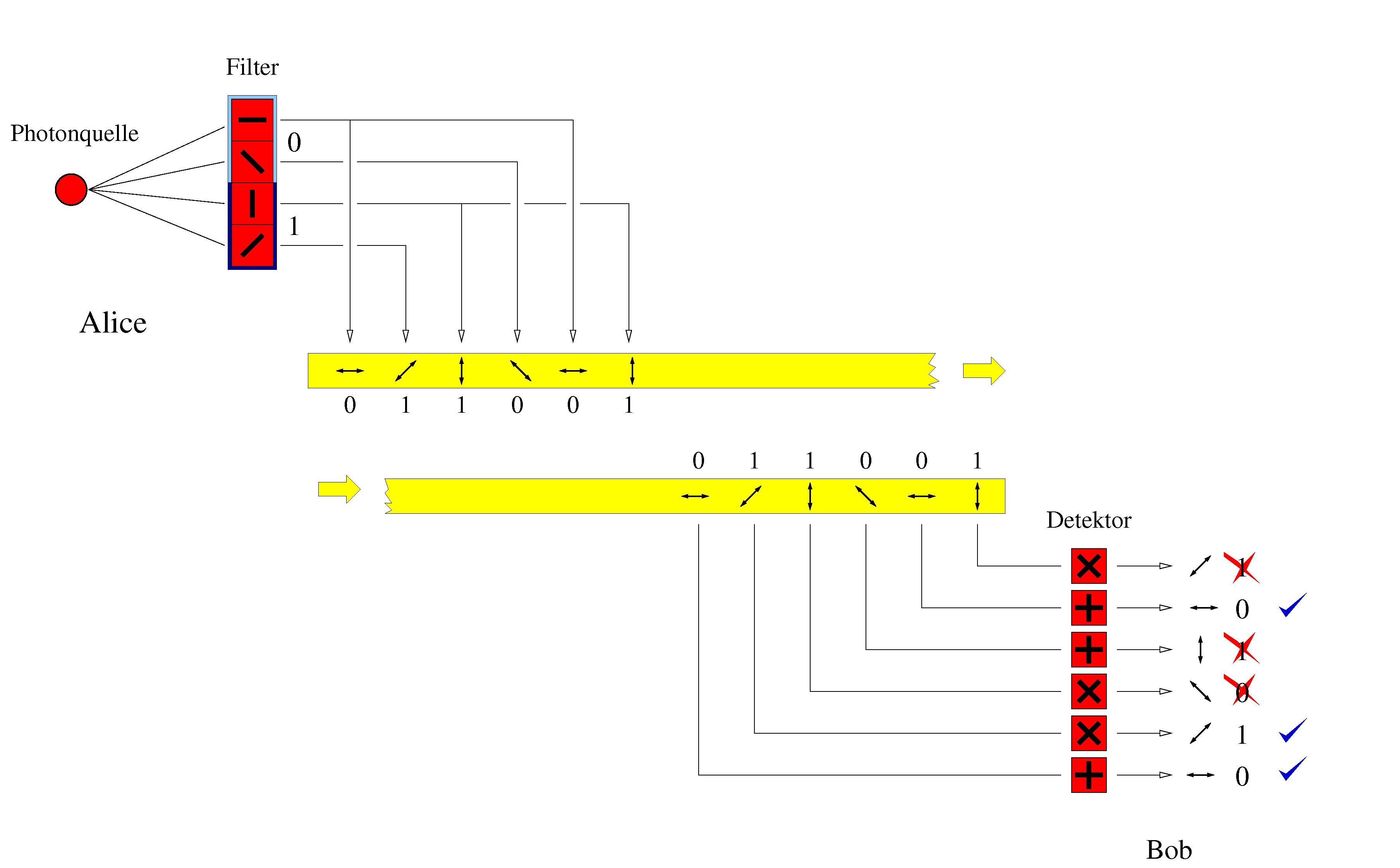
- Alice sends a sequence of photons to Bob. She picks photons polarizations randomly from horizontal, vertical, 45- and 135-degrees polarizations.
- For each photon, Bob randomly chooses one of two detectors to perform a measurement. Then he records his detectors and the results of the measurements.
- Bob announces his detectors (but not the results) publicly through the public channel that he shares with Alice. Note that it is crucial that Bob publicly announces which detector he used to the measurement after the measurement is made.
- Alice tells Bob which measurements are done with the correct detectors.
Watermarking: security in media streamsThough the problem to ensure authenticity for data has been studied intensively in the last decade in many research centres, it remains still open. Digital watermarking enables an important partial solution to this problem. The aim of such methods is to distinguish an original and a copy of multimedia data using a watermark in such a way that it is easy to extract a watermark and then with high probability to identify it correctly. The watermark should be resistant against data manipulation and it should protect against making copies illegally. Such methods should give as few noise to the original as possible making a distortion small and on the other hand they should guarantee that the watermarks are robust against data manipulations.
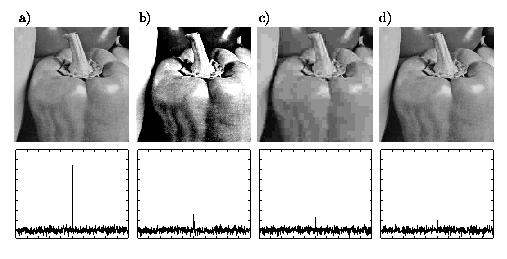
Using the Spread-Spectrum Method we have embedded a watermark in a small image (128 x 128 Pixels) -- see Fig. a. Then we test the robustness of this method against three attacks: (b) graduation attack (giving a similar effect as scanning), (c) JPEG attack with quality 6%, and (d) StirMark attack. The raw below the images shows the answers of decoder for 500 watermarks which are picked randomly. In original image there is embedded watermark nr. 250 and the answer of the detector for this situation is 32. For the remaining cases the answer is significantly smaller but for (b) and (c) it is still possible to find the embedded watermark: though the huge difference between the original image and the images (b) and (c) the detector gives the answer 8.1 resp. 6.4. On the other hand case (d) shows that the method is not robust against StirMark: the image after StirMark transformation has very good quality but the answer is only 4.9.
Knowledge Discovery in Data BasesDATA Mining also without shovel
Components of knowledge discovery
The process of the knowledge discovery consists of the following components:
1 Selection
Determination of the relevant subset of data from the total quantity, e.g. all car owners.2 Data Preprocessing
- data cleaning (removal of unnecessary details), e.g.the specification of the sex of patients having testicle cancer.
- reconfiguration (standardization of all data formats; necessary since data can stem from very inhomogeneous data sources).
3 Transformation, e.g.
- adding other useful data (e.g. demographic profile of the population)
- integration of relevant background knowledge
- then, supplying the data for the knowledge discovery process
4 Knowledge Discovery
- extraction of Patterns from the data.
- estimating the reliability of the patterns derived
5 Interpretation and Evaluation
The patterns detected must be converted into knowledge which can be used for the support of decision-making processes by humans or other programs. Visualization of the results obtained. Checking whether or not the acquired knowledge is really useful and correct.
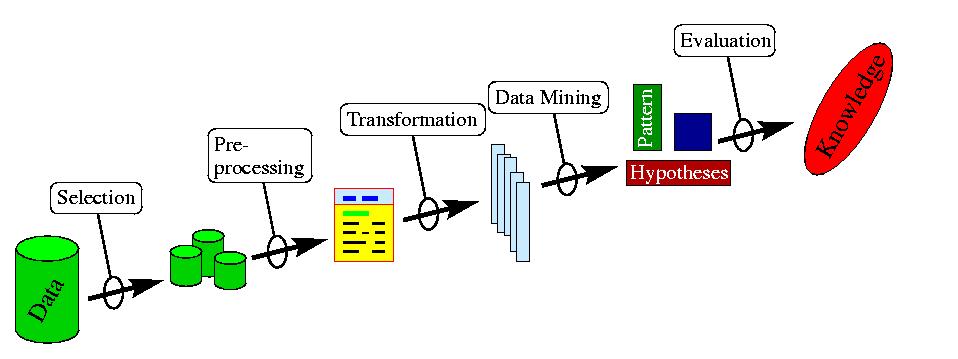
Tools for Knowledge Discovery
1) Statistics
Statistical methods are the classical tools for the data analysis. Statistics packages are often already integrated into data base systems. The most important problem is scalability, i.e., adapting available procedures so that they can also handle the enormous quantities of data to be analyzed.
2) Machine Learning Procedures
These procedures play a fundamental role during the knowledge discovery process.
Inductive Learning Procedures
Induction is the process of deriving information from the data. Inductive learning is thus the model building process during the analysis of the cleaned data.
Examples:
- learning decision trees,
- learning functional connections.

About an unknown function f we receive the following information:
f(0) = 0,
f(1) = 1,
f(2) = 2.Which function could it be?

Hah, Hah, Hah,
f(x)=x
And now:
f(3) = 720! = 1 * 2 * 3 * ... * 720 ???
Motivation
During the last two decades we are faced with an enormous growth of the data that are electronically available. The quantity of supplied data doubles itself about every 20 months.
Examples: mapping the entire human genome, astronomical data collected by satellites, business data of large companies, semi-structured data in the World Wide Web.
Goals:
Extracting the knowledge contained in the data, e.g.
- Which genes cause what in the organism?
- Which modifications of the solar activity do influence the climate on earth lastingly?
- How did the customer behavior develop in the last 6 months?
- hich new publications are on the WWW available, which of those are important for my research/developments?
Thus, the main task is to discover the knowledge implicitly contained in the data and to represent it in a form that is understandable for humans. This process is called knowledge discovery in databases.
Problems
The quantity of the data to be analyzed is enormous (GIGABYTE area). The data can be present in very inhomogeneous formats. The data are frequently incomplete and noisy (e.g. measuring errors). The task is not to retrieve individual data but to discover knowledge, i.e. the regularities hidden in the data.
Further important classes of learning procedures comprise:
Neural networks, Bayes learning, inductive logical programming, case based reasoning, instance-based learning, genetic algorithms, analytical learning, Hidden Markov models, and... many... many... more.
BUT:Learning alone is not yet knowledge discovery e.g. the hypotheses found by learning procedures can be completely incomprehensible to a biologist. Therefore, the knowledge must be represented in a form understandable to the users of a data mining system. In this regard, also visualization techniques are important. Additionally, one needs qualitative assertions about the quality of the knowledge extracted.
Example:Owners of a credit card who do not pay their debt, have characteristics A, B and C. However, if an owner of a credit card has characteristics A, B and C, then she pays her debts with 10% probability.
Thus, the problem arises whether or not one should lock all credit cards of customers satisfying characteristics A, B and C, thereby possibly discriminating good customers.
DaMiT (Data Mining Tutor)
DaMiT is a nation wide project promoted by the BMBF within the future investment program.
Partners in the network project DaMiT are
- TU Darmstadt
- TU Chemnitz
- University of the Saarland (Saarbrücken)
- TU Ilmenau
- University of Freiburg
- Brandenburgische Technical University atCottbus
- University of Kaiserslautern
- University of applied sciences at Wismar
- Otto-von-Guericke-University Magdeburg
- Medical University at Lübeck
Partner at the Medical University at Luebeck is Professor Dr. Thomas Zeugmann
Erstellt 07. December 2001, Claudia Mamat
