Medizinische Universität zu Lübeck
|
Institut für
Theoretische Informatik
Medizinische Universität zu Lübeck |
Lübecker Hochschultag
15. November 2001 Verteilte Systeme
Verteilte SystemeDas Problem der byzantinischen Generäle
(hier: der römischen Zenturionen)
Der Hintergrund:
Wir befinden uns im Jahre 50 v. Chr. Ganz Gallien ist von den Römern besetzt ... Ganz Gallien? Nein! Ein von unbeugsamen Galliern bevölkertes Dorf hört nicht auf, den Eindringlingen Widerstand zu leisten.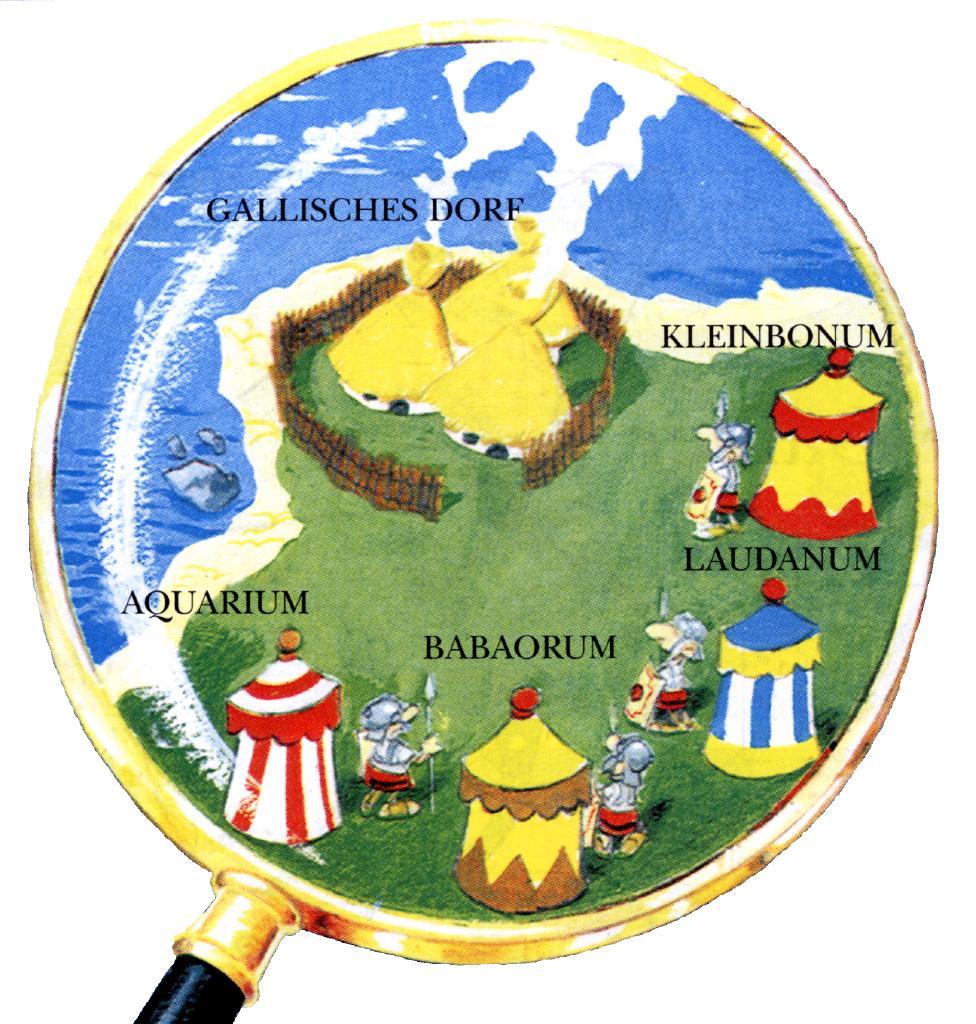
Um das Dorf warten mehrere römische Legionen auf eine günstige Gelegenheit zum Angriff. Wenn die Legionen nicht gleichzeitig angreifen würden, könnten sie leicht von den Galliern besiegt werden.
Die Zenturionen können sich nur durch Boten verständigen, da sie anderenfalls ihre Legion allein lassen müßten. Aber es könnten sich Zenturionen von den Galliern bestechen lassen. Die bestochenen Zenturionen würden widersprüchliche Nachrichten senden, so daß einige Legionen angreifen, während andere den Rückzug antreten würden.
Die Frage:
Wie können sich die Zenturionen mit Hilfe der Boten Aufschlag angreifen oder abziehen einigen, obwohl einige von ihnen bestochen wurden?
Die Lösung:
Die Zenturionen können sich auf eine Strategie einigen, wenn mindestens zwei Drittel der Zenturionen loyal sind. Als Beispiel beschreiben wir das Vorgehen, falls es vier römische Lager gibt: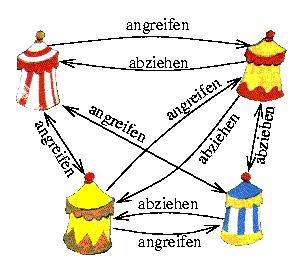
Zunächst schickt jeder Zenturio an jeden anderen Zenturio einen Boten, um mitzuteilen, ob er angreifen oder abziehen möchte. Ein loyaler Zenturio wird allen anderen das Gleiche mitteilen, ein bestochener Zenturio hält sich an die Befehle der Gallier.

Danach teilt jeder Zenturio jedem anderen mit, was er von den Kollegen für eine Nachricht erhalten hat. Wieder teilt ein bestochener Zenturio mit, was die Gallier ihm auftragen. Jeder Zenturio kann sich nun anhand der empfangenen Nachrichten für angreifen oder abziehen entscheiden. Es ist sichergestellt, daß sich alle loyalen Zenturionen für die gleiche Strategie entscheiden.
Es läßt sich beweisen, daß sich das Problem für jede Anzahl von Zenturionen lösen läßt, wenn mindestens zwei Drittel der Zenturionen loyal sind. Andererseits kann in dem Fall, daß die Gallier mindestens ein Drittel der Zenturionen bestechen, keine Einigung erzielt werden.
Was hat das mit verteilten Systemen zu tun?
Bei Berechnungen in verteilten Umgebungen, wie z.B. mehreren Computern, die durch ein Netzwerk verbunden sind, gibt es Probleme, die auf einzelnen Rechnern nicht auftreten. Ein Beispiel ist das Finden von Mehrheitsentscheidungen in fehlertoleranten Systemen.Und außerhalb Galliens:
Weitere Fragestellungen im Bereich verteilte Systeme betreffen unter anderem die Verteilung von Nachrichten oder die Synchronisation.Bei der Verteilung von Nachrichten (Broadcasting) gibt es gegenläufige Ziele. Zum einen sollen die Nachrichten möglichst schnell die entsprechenden Empfänger erreichen. Auf der anderen Seite sollten so wenige Nachrichten wie möglich das Netzwerk belasten. Ein weiterer wichtiger Punkt ist die Wahl eines möglichst günstigen, d.h. schnellen oder wenig belasteten, Weges (Routing).
Wenn mehrere Prozesse gleichzeitig in die gleiche Datei schreiben möchten, kann es zu Konflikten kommen. Ein ähnliches Problem tritt auf, wenn ein Prozess eine Datei lesen möchte, während ein anderer Prozess in diese Datei schreibt. In diesen Fällen ist eine Synchronisation der Prozesse notwendig, d.h. es muß sichergestellt werden, daß zunächst ein Prozess seine Arbeit mit der Datei abschließt, bevor ein anderer Prozess Zugriff auf diese Datei erhält.
Die Bilder sind entnommen aus: R. Goscinny und A. Uderzo, Asterix und Latraviata.
Average-Case Untersuchung
Optimist, Pessimist und Joe Average
Bei der Analyse von Algorithmen spielen vor allem drei Betrachtungsweisen eine entscheidende Rolle:
- die optimistische Betrachtungsweisen, welche den Best-Case beschreibt,
- die gemittelte Betrachtungsweisen, welche den Average-Case beschreibt und
- die pessimistische Betrachtungsweisen, welche den Worst-Case beschreibt.
Die Average-Case Analyse beschäftigt sich mit der Untersuchung des durchschnittlichen Aufwands. Für viele Probleme können Average- und Worst-Case weit auseinander liegen. Der Unterschied kann an folgendem einfachen Beispiel gezeigt werden:
Im Worst-Case ist die gegebene Zahl die 99999 und wir müssen insgesamt 6 Stellen verändern. Bestimmen wir die Eingabezahl aber zufällig, so müssen wir mit einer Wahrscheinlichkeit von 9/10 nur die letzte Ziffer (welche keine 9 ist) ändern. Die Wahrscheinlichkeit das wir zwei Ziffer ändern müssen ist 1/10 * 9/10 = 9/100, und so weiter. Im Erwartungswert müssen also1 * 9/10 + 2 * 9/100 + 3 * 9/1000
+ 4 * 9/10000 + 5 * 9/100000 + 6 * 1/100000
= 1,1111Stellen ändern, was sehr nahe am Best-Case von einer Stelle liegt. Egal wie lang die Eingabezahl ist, im Erwartungswert müssen nicht mehr als 1,11... Stellen geändert werden.
Fragen wir also einen Optimisten, wie lange er benötigt, um eine Zahl um 1 zu erhöhen, so geht er davon aus, daß die letzte Ziffer keine 9 ist, er müßte somit nur eine Stelle ändern. Der Pessimist geht von der 99999 aus und müßte daher 6 Stellen ändern. Joe Average, der in Deutschland auch Otto Normalverbraucher genannt wird, ist davon überzeugt, 2 Stellen ändern zu müssen ... mit sehr hoher Wahrscheinlichkeit.
Fragen dieser Art tauchen immer dann auf, wenn sich zeigt, daß ein Problem für viele Eingaben sehr einfach ist, jedoch in manchen Fällen nur mit erheblichen Aufwand gelöst werden kann. Besonders interessant ist dieses für kombinatorisch sehr aufwendige Probleme, da sich hier für manche Fragestellungen (wie zum Beispiel dem Puzzlespiel) zeigen läßt, daß sie auch im Average-Case annähernd so schwer sind wie im Worst-Case. Betrachtungen dieser Art werden nicht nur für die Lösung einzelner Probleme durchgeführt, sondern spielen auch für die Kommunikation und Sicherheit im Internet oder über der Generierung von Passwörtern eine entscheidende Rolle. Wer möchte schon eine Nachricht verschlüsseln oder ein Passwort benutzen, wenn die Entschlüsselung manches mal sehr schwer, jedoch in den meisten Fällen einfach ist.
Ein weiteres Forschungsfeld, in dem die Average-Case Untersuchung zur Anwendung kommt ist die Optimierung von Algorithmen. Ein Verfahren, welches erwartungsgemäß eine Laufzeit von n2 auf Eingaben der Länge n hat und nur auf 1/n4 aller Eingaben eine Laufzeit von n4 wird mit sehr großer Wahrscheinlichkeit für die ersten n2 Eingaben immer schnell sein.
Approximationsalgorithmen
Schwere Probleme näherungsweise schnell gelöst
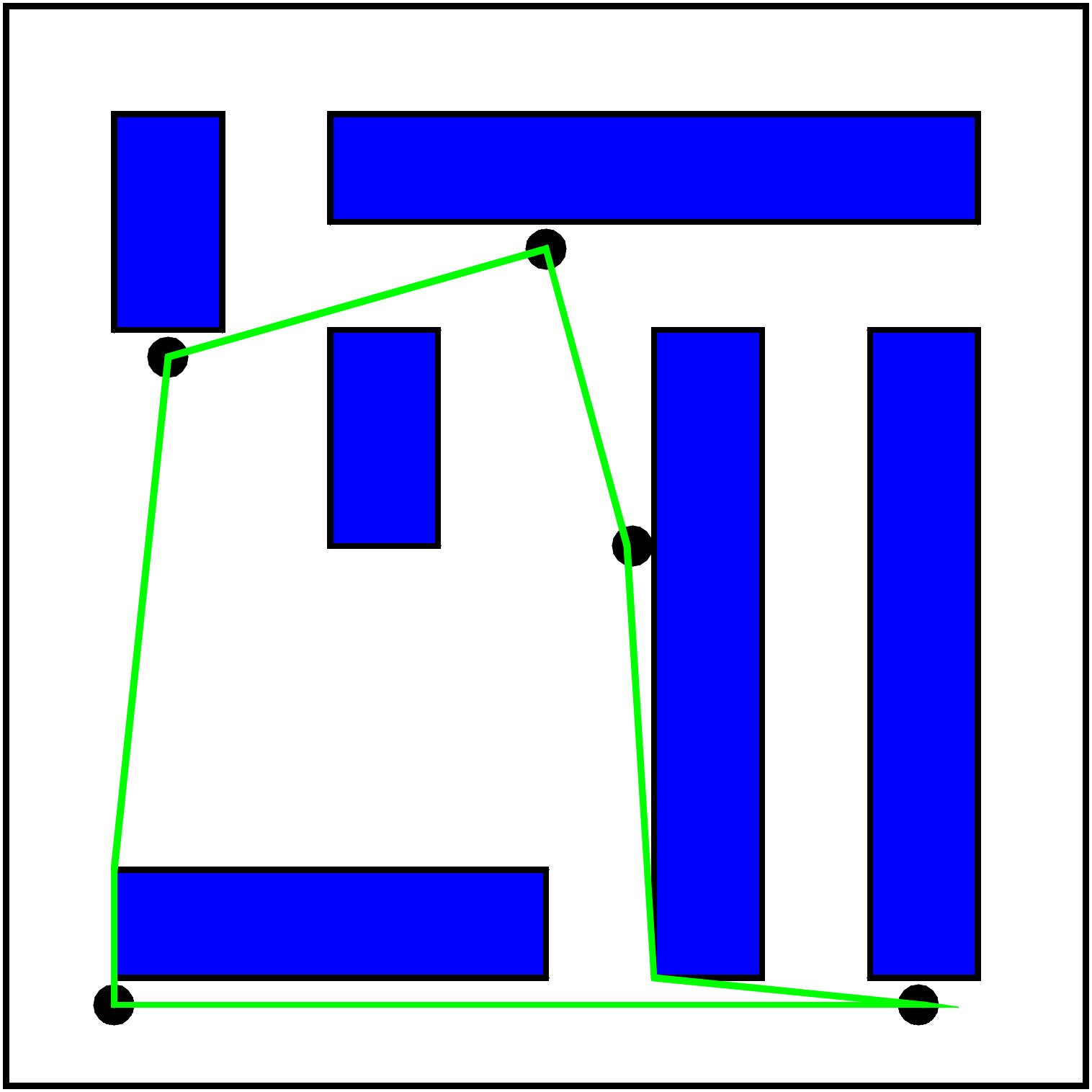
Roboter Fred arbeitet in dem Lager eines Versandhaus. Mit dem nächsten Paket sollen ein Pullover, ein Paar Socken, eine Hose, sowie ein T-Shirt versandt werden. Diese befinden sich im Lager an den Punkten 2,3,4 und 5, Fred selbst startet in 1. Damit möglichst viele Pakete verschickt werden können, soll Fred die Punkte 2,3,4 und 5 auf dem kürzesten Weg abfahren und dann wieder nach 1 zurückkehren (Rundreise).
Leider benötigen die besten bekannten Algorithmen, um eine kürzeste Rundreise, die n Punkte besucht, zu berechnen, im allgemeinen Zeit cn (für eine Konstante c). Dies kann schnell sehr groß werden, so ergibt sich z.B. für c = 2 und n = 100 eine Rechenzeit von 4 * 106 Jahren (auf einem modernen PC).
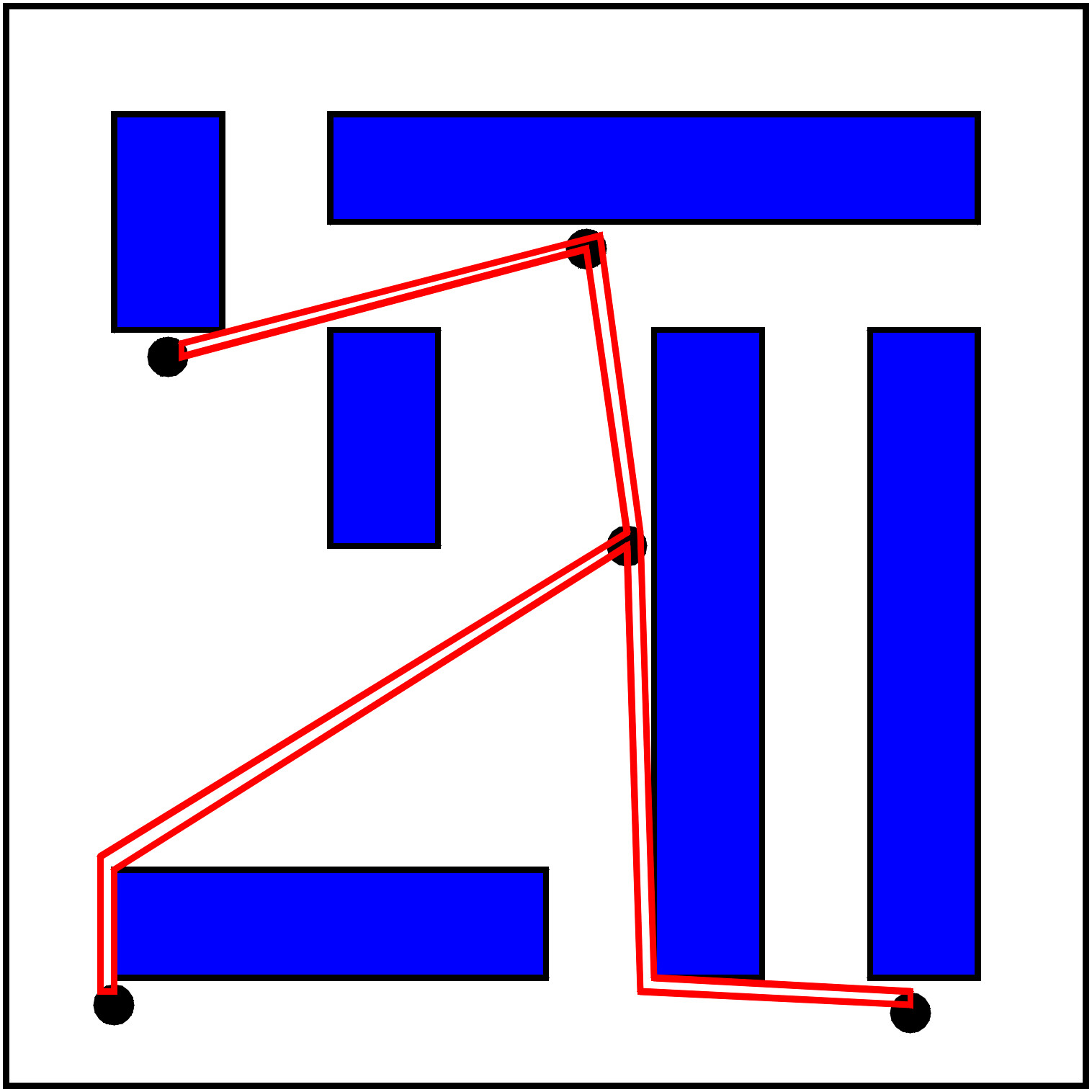
Daher betrachtet Fred folgende alternative Möglichkeit, die Punkte 1 bis 5 zu besuchen: Ein Spannbaum verbindet die Punkte 1 bis 5 mit einer minimalen Anzahl von Kanten. Ein Spannbaum, für den die Summe der einzelnen Kantenlängen minimal ist, kann jedoch schnell berechnet werden, nämlich in Zeit c * n. Für c = 1000 und n = 100 sind dies nur 0,1 Sekunden.
Den Spannbaum reist Fred wie folgt ab: Er startet in 1 und besucht dann z.B. 4 und danach 3. Da von hier kein Weg weiterführt, geht er zurück nach 4. Auch hier führt kein Weg weiter, also geht er nochmals zurück nach 1, dann nach 2, zurück nach 1, schließlich nach 5 und wieder nach 1.
Solch eine optimale Spannbaumreise ist aber maximal doppelt so lang wie eine optimale Rundreise, da jede Rundreise nach Löschen einer Kante ein Spannbaum ist und jede Kante in der Spannbaumreise zweimal besucht wird.
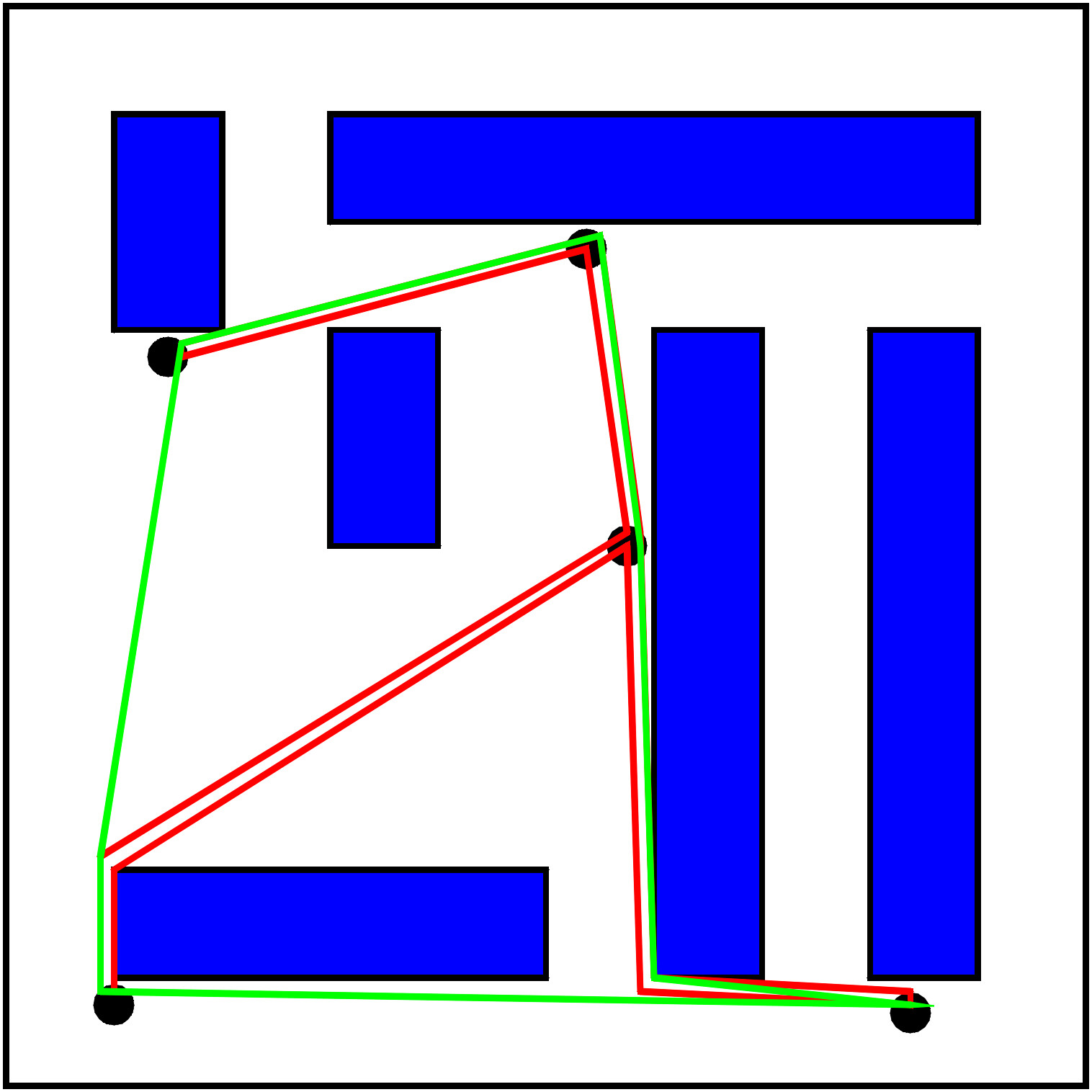
Eine Spannbaumreise kann aber leicht in eine Rundreise verwandelt werden, die nicht länger als die Spannbaumreise ist, indem man Abkürzungen nimmt. In unserem Beispiel besucht Fred nach den Punkt 1, 4 und 3 nicht wieder 4 sondern geht direkt nach 2. Von dort geht er nicht nach 1, sondern weiter nach 5 und dann erst wieder nach 1. Dies beendet seine Rundreise.
Da diese Abkürzungen den Gesamtweg nicht verlängern, erhält Fred so eine Rundreise, die höchstens doppelt so lang ist wie die optimale. Aber oftmals kann dies sogar viel besser sein. Z.B. findet Fred hier sogar die optimale Rundreise.
Neben dem oben beschriebenen Problem der kürzesten Rundreise haben viele weitere praxisrelevante Probleme die Eigenschaft, daß die besten bekannten Algorithmen zur exakten Lösung des Problems exponentiell viel Zeit benötigen. Weitere Beispiele sind das Verteilen von Jobs auf Prozessoren oder das Platzieren von Warenlagern. Hier helfen Approximationsalgorithmen gute Lösungen in akzeptabler Zeit zu finden.
Formale SprachenGeheimnisvolle Symbolik mit bunten Kreisen
Wollen wir etwas mitteilen, so setzt dies Sprache voraus. In dieser Form werden Programmiersprachen, natürliche Sprachen, Formelsprachen, Druckersprachen und viele andere Sprachen vielerorts eingesetzt. Bevor wir die Bedeutung eines Satzes oder eines Wortes in einer solchen Sprache klären können, müssen wir prüfen, ob der Satz bzw. das Wort zu dieser Sprache gehört. Allen diesen Sprachen ist gemein, dass sie eine innere Struktur aufweisen, mit der festgelegt ist, welche Sätze, Wörter oder Zeichenreihen zu der Sprache gehören und welche nicht. Bei allen formell festgelegten Sprachen gibt es dafür Regeln, die es zu überprüfen gilt. Hier wollen wir demonstrieren, dass wenige Regeln ausreichen, um eine Sprache festzulegen, für die wir kein(!) Programm schreiben können, das prüft, ob eine Zeichenfolge dazugehört.
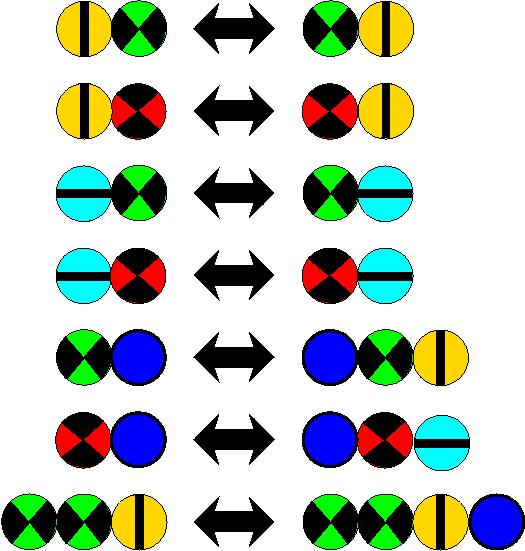
Hier betrachten wir ein Regelsystem, mit dem wir Folgen von bunten Kreisen manipulieren können. Um zu verstehen, was dabei vorgeht, möchten wir wissen, welche Folgen von bunten Kreisen in welche Folgen überführt werden können. In einer gegebenen Folge dürfen wir einen zusammenhängenden Teil gemäß der Regeln ersetzen --- wir dürfen die Regeln von links nach rechts und auch von rechts nach links anwenden. Natürlich sind wir als Informatiker in der guten Lage, dass wir einfach ein Programm für diese Fragestellung schreiben können. Überraschend mag es jedoch für viele sein: Für die hier dargestellten Regeln hat der Russe Chaitin bewiesen: Es gibt kein Programm, welches für beliebige zwei Folgen von bunten Kreisen ausgibt, ob diese ineinander überführt werden können!
Seht das folgende Beispiel, es mag ein wenig die entstehenden Schwierigkeiten demonstrieren:
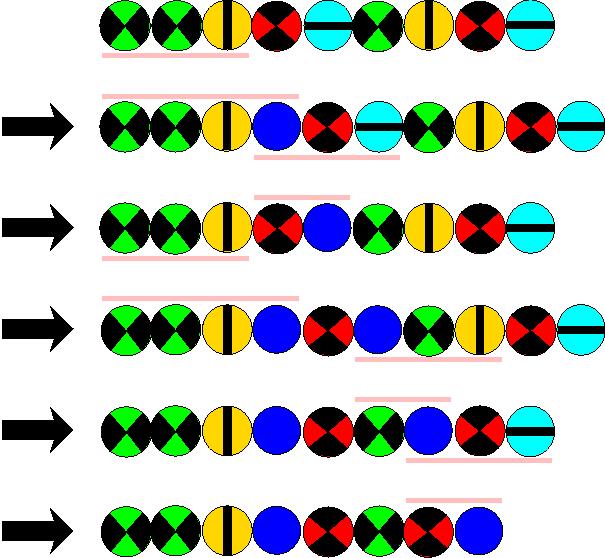
Für das oben angegebene Regelsystem kann man zahlreiche Aussagen beweisen. Beispielsweise:
- Die Anzahl der Kreise mit roter Farbe bleibt konstant.
- Die Anzahl der Kreise mit grüner Farbe bleibt konstant.
- Wenn eine Kette in eine andere überführbar ist, so haben diese beiden Ketten die Eigenschaft, dass sie einander gleichen, wenn alle bis auf die roten und grünen Kreise entfernt werden.
Schließlich beweist Chaitin: Jedes Programm einer Programmiersprache mit Eingabe kann in zwei Folgen von obigen Kreisen mit Hilfe eines Übersetzungsprogramms übersetzt werden, so dass folgendes gilt: Das eingegebene Programm produziert mit seiner Eingabe eine Ausgabe genau dann, wenn die beiden Folgen mit Hilfe der sieben Regeln in einander überführbar sind.Da man kein Programm schreiben kann, das für alle Paare von Programm und Eingabe entscheidet, ob das Paar eine Lösung liefert, ist das Überführungsproblem für diese sieben Regeln nicht entscheidbar.
SicherheitHeute und in der Zukunft
Bei dem RSA-Kryptosystem (benannt nach seinen Erfindern Rivest, Shamir und Adleman) handelt es sich um ein Public Key Krypto-System. Es wird zum Beispiel von PGP verwendet. Der Algorithmus funktioniert wie folgt:
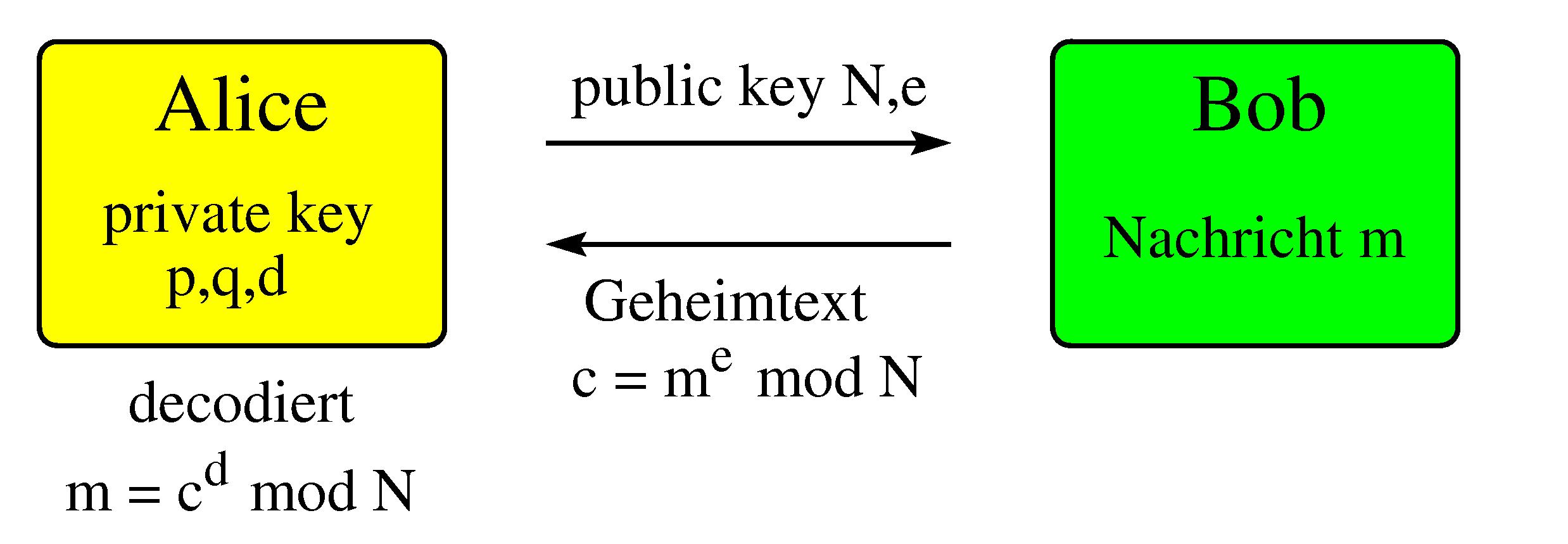 Alice wählt zwei große Primzahlen p und q und berechnet N = p q und phi = (p-1) (q-1). Dann wählt sie e aus {1,2,...,phi} mit ggT(e,phi) = 1 und berechnet d mit (d e) mod phi = 1 (dies geht z.B. mit dem erweiterten Euklidischen Algorithmus)
Alice wählt zwei große Primzahlen p und q und berechnet N = p q und phi = (p-1) (q-1). Dann wählt sie e aus {1,2,...,phi} mit ggT(e,phi) = 1 und berechnet d mit (d e) mod phi = 1 (dies geht z.B. mit dem erweiterten Euklidischen Algorithmus)Die Zahlen
- N und e sind Alice öffentlicher Schlüssel (public key), den sie z.B. Bob aber auch allen anderen Personen mitteilen darf.
- p, q und d sind Alice privater Schlüssel (private key), den sie geheim hält.
Möchte Bob nun eine Nachricht an Alice schreiben, so teilt er diese in Blöcke und wandelt jeden Block in eine Zahl m kleiner gleich N um (z.B. mit dem ASCII-Code). Dann berechnet Bob c = me mod N und übermittelt jeweils c an Alice. Alice kann nun aus c wie folgt dekodieren: m = cd mod N. Das dies funktioniert folgt aus dem sog. Satz von Euler.Was Public-Key Systeme auszeichnet, ist die Tatsache, dass obwohl man weiß, wie die Nachricht verschlüsselt wurde, es schwer ist, die Nachricht zu entschlüsseln, ohne Alice privaten Schlüssel zu kennen.
Sicherheit von Kryptosystemen
Die Sicherheit von Kryptosystemen basiert auf der Schwierigkeit, konkrete Probleme (konventionell) zu lösen, im Fall von RSA ist dies die Schwierigkeit des Faktorisierens großer Zahlen, also aus N wieder die Zahlen p und q zu errechnen.
Faktorisierung
Das Problem:
Berechne für eine gegebene Zahl N deren Primfaktoren!Beispiel:
(1) Für N = 15 sind die Primfaktoren 3 und 5.
Aufgabe:
(2) Für N = 39199007823998693533 lautet die Antwort 4093082899 und 9576890767.
(3) Versuchen Sie für N = 2630492240413883318777134293253671517529 die Primfaktoren zu finden!Die besten heute bekannten klassischen Algorithmen benötigen zum Faktorisieren einer Zahl N (auf einem modernen Rechner)
exp(1.9 (ln N)1/3 (ln ln N)2/3)
Mikrosekunden. Das ergibt im Fall (2) 21.26 Sekunden und im Fall (3) 5.74 Minuten. Hat die Zahl N eine Dezimaldarstellung mit 65 bzw. 400 Ziffern, dann brauchen obige Algorithmen 89 Tage bzw. etwa 1010 Jahre (Dies ist das Alter des Universums!). Es wird vermutet, dass es keinen (konventionellen) Algorithmus gibt, der effizient große Zahlen faktorisiert. Dies würde bedeuten, dass das RSA-System mit konventionellen Rechnern nicht zu brechen ist.
Quantenrechner --- schwere Probleme leicht gemacht
Im 1994 hat Peter Shor (AT&T) einen Quantenalgorithmus entdeckt, der eine Zahl N in Zeit: c * (ln N)3, wobei c eine kleine Konstante ist, faktorisieren kann! Das heißt, für eine Zahl mit 400 Ziffern braucht ein Quantenrechner nur 3 (statt 1010) Jahre.
Problem: Bis jetzt gibt es nur Prototypen des Quantenrechners (bis zum 3 Quantenbits).
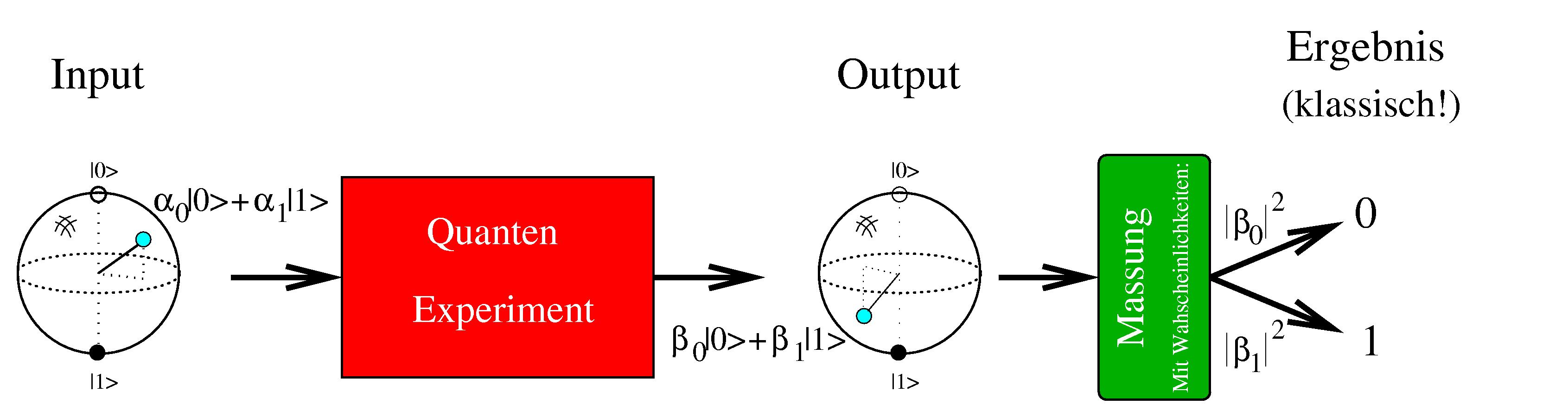
Wie funktionieren Quantenrechner?
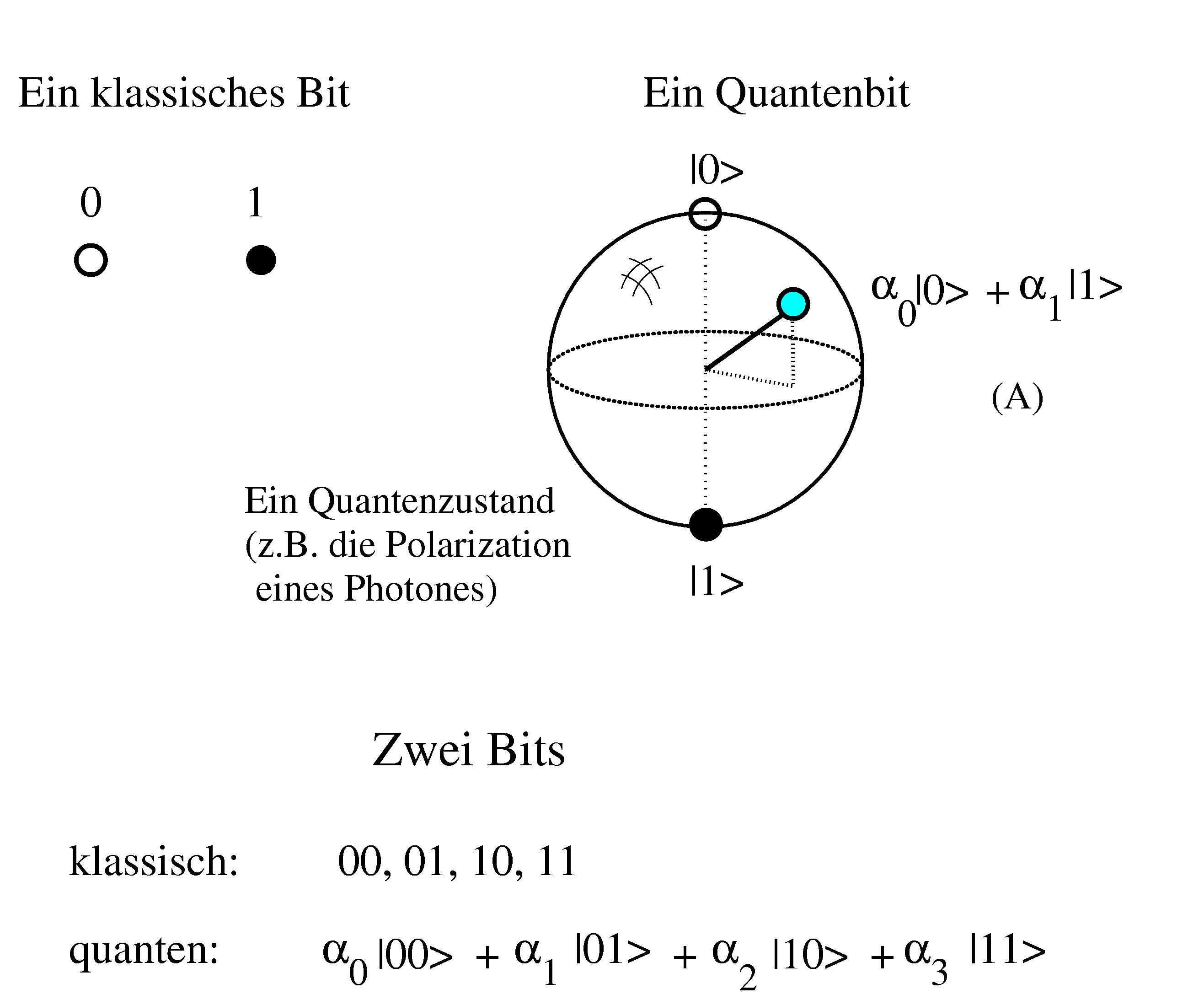
Wobei alpha0, alpha1 beliebige komplexe Zahlen sind, so dass |alpha0|2 + |alpha1|2 =1.
Ein-Qbit-Quantenrechner
Quantenkryptosysteme
Alice und Bob senden Folgen von Photonen. Einen Quantenrechner benötigen sie nicht!
Wichtige Eigenschaften:
- No-Cloning: Ein nicht bekannter Quantenzustand kann nicht kopiert werden.
- Informationsgewinn impliziert Störung: Der Versuch, zwischen zwei nichtorthogonalen Quantenzuständen zu unterscheiden, zieht immer eine Störung des Signals nach sich.
- Irreversibilität der Messungen: Im allgemeinen wird der Zustand des untersuchten Objekts von Messungen gestört.
Als Beispiel, betrachten wir ein Photon in einer der vier möglichen Polarisationen
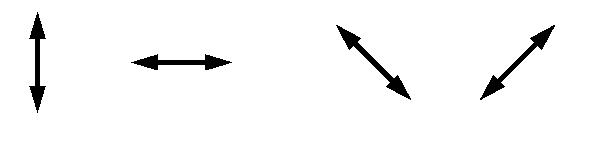
Zur Messung kann ein Kalzium-Kristall verwendet werden, um mit Sicherheit zwischen horizontal und vertikal polarisierten Photonen zu unterscheiden. Photonen, die sich ursprünglich in einer dieser beiden Polarisationen befanden, werden also deterministisch geleitet. Jedoch besagt das Gesetz der Quantenmechanik, dass ein Photon, welches sich in einer anderen Polarisation befindet, eine gewisse Wahrscheinlichkeit hat, dem einen oder anderen Strahl zu folgen. Es wird dann entsprechend polarisiert und vergisst seine ursprüngliche Polarisation.
Das Schema von Bennett und Brassard (1984)
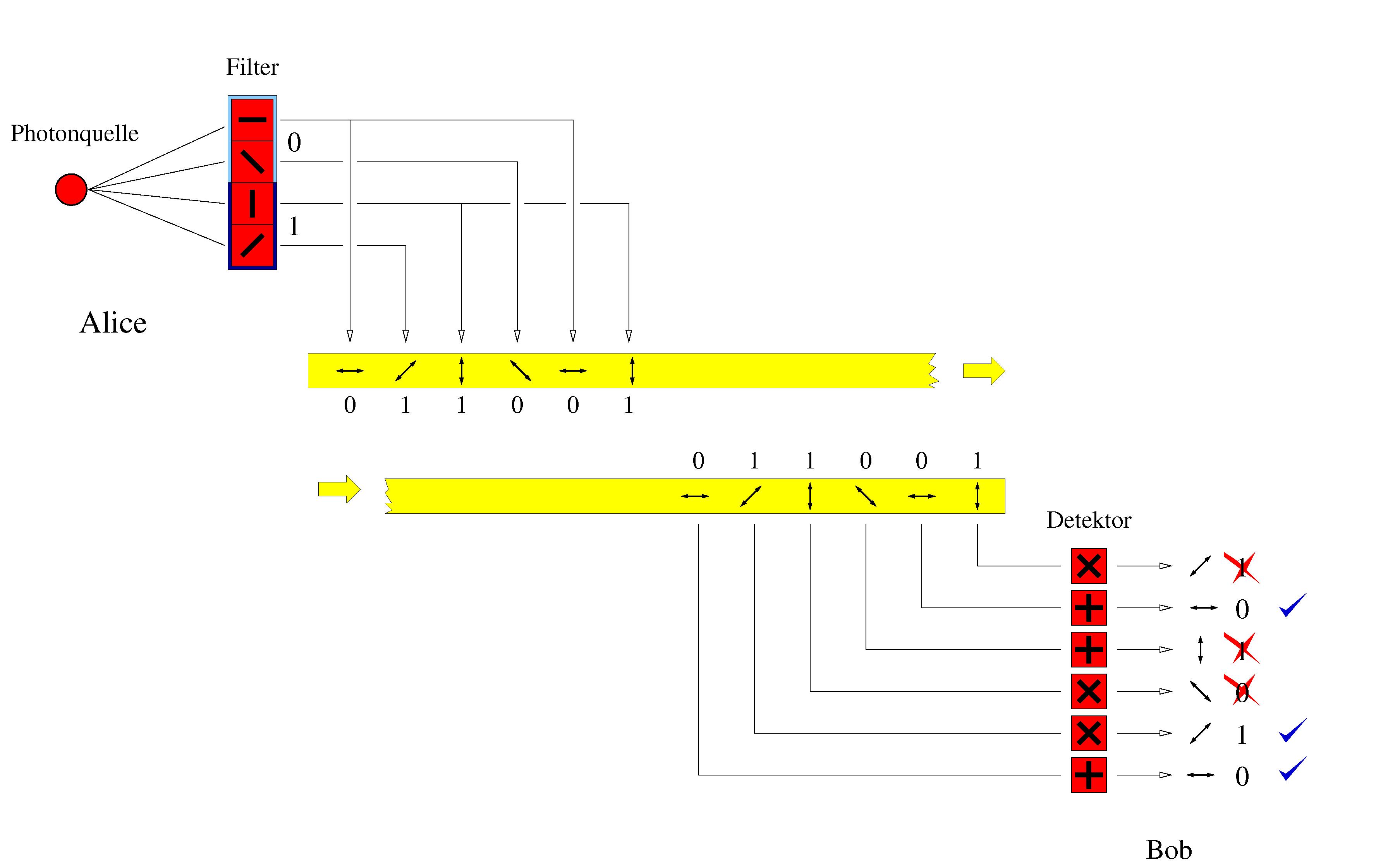
- Alice sendet eine Folge von Photonen an Bob. Diese Photonen befinden sich rein zufällig und unabhängig in einer der vier Polarisationen.
- Bob wählt für die Messung eines jeden Photons rein zufällig einen der beiden Detektoren. Bob merkt sich die verwendeten Detektoren und die dazugehörigen Ergebnisse.
- Bob nutzt den öffentlichen Kanal, um Alice mitzuteilen, welche Detektoren er benutzt hat. Seine Ergebnisse bleiben geheim. Entscheidend ist, dass Bob die jeweils verwendeten Detektoren erst nach der Messung übermittelt. Sonst hätte eine Lauscherin Eve dasselbe Wissen wie Bob und könnte einen erfolgreichen Angriff durchführen.
- Alice teilt Bob mit, welche Messungen mit der korrekten Detektoren vorgenommen wurden.
Wasserzeichen: Sicherheit in MedienströmenSeit Beginn der neunziger Jahre wird das Problem der Gewährleistung von Authentizität der Daten in vielen Forschungszentren sehr intensiv erforscht, aber bis jetzt ist es ungelöst. Digitale Wasserzeichenverfahren ermöglichen eine wichtige partielle Lösung für diese Problematik. Das Ziel solcher Methoden ist es, Original und Kopien der multimedialen Dateien mit Hilfe der Wasserzeichen unterscheiden zu können, wobei das Wasserzeichen leicht zu extrahieren und dann mit großer Wahrscheinlichkeit korrekt zu identifizieren sein muss. Dies würde Datenmanipulationen verhindern und den Eigentümer der Daten davor schützen, dass Dritte unauthorisiert Kopien erstellen. Derartige Verfahren sollten einerseits möglichst wenig Veränderungen (Rauschen) in dem Originaldaten verursachen, so dass die Verzerrung (distortion) klein ist, anderseits sollte das Wasserzeichen robust gegen Manipulationen sein.
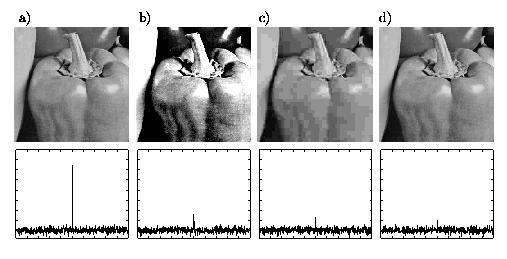
In einem Bild (128 x 128 Pixel) wird mit Hilfe der Spread-Spectrum Methode ein Wasserzeichen versteckt (Bild a). Wir testen die Robustheit der Methode gegenüber drei Attacken: (b) graduationattack (ein Effekt ähnlich wie beim Scannen), (c) JPEG Attacke mit Qualität 6%, und (d) StirMark Attacke. Die Zeile unten zeigt die Antworten des Detektors für 500 zufällig generierte Wasserzeichen. Im Originalbild wird das Wasserzeichen 250 versteckt und die Antwort des Detektors für dieses Zeichen in (a) ist 32, für die anderen Zeichen ist die Antwort gering. Trotz großer Änderungen findet der Detektor nach den Attacken (b) und (c) immer noch dieses Wasserzeichen: 8.1 bzw. 6.4. Gegenüber der StirMark Attacke ist die Methode nicht robust: Die Antwort des Detektors ist nur 4.9.
WissensentdeckungData Mining auch ohne Schaufel
Komponenten der Wissensentdeckung
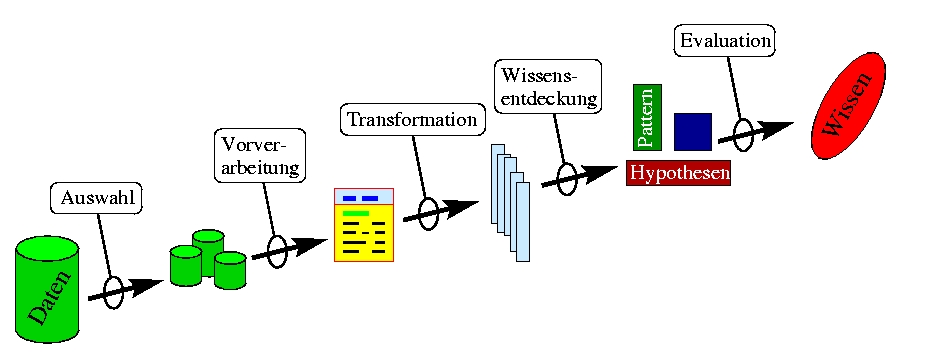
Der Prozess der Wissensentdeckung besteht aus folgenden Komponenten:
1 Auswahl
Bestimmung der relevanten Teilmenge von Daten aus der Gesamtmenge, z.B. alle Autobesitzer.2 Datenvorverarbeitung
- Datensäuberung (Beseitigung unnötiger Details), z.B. der Angabe des Geschlechts bei Hodenkrebspatienten.
- Rekonfiguration (Vereinheitlichung aller Datenformate, nötig da Daten aus sehr inhomogenen Quellen stammen können).
3 Transformation, z.B.
- Hinzufügen anderer nützlicher Daten (z.B. demographisches Profil der Bevölkerung)
- Integration von relevantem Vorwissen
- Endgültiges Bereitstellen der Daten für den Wissensentdeckungsprozess
4 Wissensentdeckung
- Extraktion von Pattern, d.h. Mustern, aus den Daten.
- Abschätzung der Zuverlässigkeit der abgeleiteten Pattern
5 Interpretation und Evaluierung
Erkannte Pattern müssen in Wissen umgewandelt werden, das zur Unterstützung von Entscheidungsprozessen durch Menschen oder andere Programme verwendet werden kann. Visualisierung der gewonnenen Ergebnisse. Ist das erworbene Wissen wirklich nützlich und richtig.
Werkzeuge der Wissensentdeckung
1) Statistik
Statistische Methoden sind die Klassiker der Datenanalyse. Statistikpakete sind oft schon in Datenbanksysteme integriert. Wichtigste Aufgabe: Skalierung der vorhandenen Verfahren, so dass auch riesige Datenmengen ausgewertet werden können.
2) Maschinelle Lernverfahren
Diese Verfahren spielen eine fundamentale Rolle im Wissensentdeckungsprozess.
Induktive Lernverfahren
Induktion ist der Prozess des Ableitens von Informationen aus den Daten. Induktives Lernen ist somit der Modellbildungsprozess während der Analyse der vorbereiteten Daten.
Beispiele:
- Lernen von Entscheidungsbäumen,
- Lernen funktionaler Zusammenhänge.

Über eine unbekannte Funktion f erhalten wir folgende Informationen:
f(0) = 0,
f(1) = 1,
f(2) = 2.Um welche Funktion könnte es sich handeln?

Hah, Hah, Hah,
f(x)=x
Und jetzt:
f(3) = 720! = 1 * 2 * 3 * ... * 720 ???
Motivation
In den letzten beiden Dekaden haben wir ein enormes Wachstum der elektronisch verfügbaren Daten zu verzeichnen. Etwa alle 20 Monate verdoppelt sich die Menge der bereitgestellten Daten.
Beispiele: Kartographierung des menschlichen Genoms, astronomische Daten, die von Satelliten gesammelt werden, Geschäftsdaten großer Firmen, semistrukturierte Daten im World-Wide-Web.
Aufgabe
Extrahierung des in den Daten enthaltenen Wissens, z.B.
- Welche Gene bewirken was im Organismus?
- Welche Veränderungen der Sonnenaktivität beeinflussen das Klima auf der Erde nachhaltig?
- Wie hat sich das Kundenverhalten in den letzten 6 Monaten entwickelt?
- Welche neuen Publikationen sind im WWW verfügbar, die für meine Forschungen/Entwicklungen bedeutsam sind?
Es kommt also darauf an, das in den Daten vorhandene Wissen zu entdecken und in einer für Menschen verständlichen Form darzustellen. Dieser Prozess wird Wissensentdeckung in Datenbasen genannt.
Probleme
Die Menge der zu analysierenden Daten ist riesig (GIGABYTE Bereich). Die Daten können in sehr inhomogener Form vorliegen. Die Daten sind häufig unvollständig und mit Fehlern behaftet (z.B. Messfehler). Es kommt nicht darauf an, einzelne Daten abzufragen, sondern Wissen, d.h. die in den Daten verborgenen Gesetzmässigkeiten, aufzuspüren.
Weitere bedeutende Klassen von Lernverfahren umfassen:
Neuronale Netzwerke, Bayessches Lernen, Induktives Logisches Programmieren, Fallbasiertes Lernen, Instanzenbasiertes Lernen, Genetische Algorithmen, Analytisches Lernen, Hidden Markov Modelle und ... viele ... viele ... andere
ABER: Lernen alleine ist noch nicht Wissensentdeckung z.B. Die von Lernverfahren gefundenen Hypothesen können für einen Biologen gänzlich unverständlich sein. Das Wissen muss also noch in eine für Anwender verständliche Form gebracht werden. In diesem Zusammenhang sind auch Visualisierungstechniken bedeutsam. Man braucht qualitative Aussagen über die Güte des extrahierten Wissens.
Beispiel: Kreditkartenbesitzer, die ihre Rechnungen nicht bezahlen, haben Eigenschaften A, B und C. Aber, wenn ein Kreditkartenbesitzer Eigenschaften A, B und C hat, so bezahlt er seine Rechnungen mit 10%-iger Wahrscheinlichkeit.
Soll man also die Kreditkarten aller Besitzer mit Eigenschaften A, B und C sperren, und damit auch gute Kunden verprellen?
DaMiT (Data Mining Tutor)
DaMiT ist ein vom BMBF im Rahmen des Zukunftsinvestitionsprogramms gefördertes bundesweites Projekt.
Partner im Verbundprojekt DaMiT sind
- TU Darmstadt
- TU Chemnitz
- Universität des Saarlandes (Saarbrücken)
- TU Ilmenau
- Universität Freiburg
- Brandenburgische Technische Univ. Cottbus
- Universität Kaiserslautern
- Hochschule Wismar
- Otto-von-Guericke-Universität Magdeburg
- Medizinische Universität Lübeck
Ansprechpartner an der Medizinische Universität Lübeck ist Prof. Dr. Thomas Zeugmann.
Erstellt 07. November 2001, Claudia Mamat
